Dowiedz się, czym jest fuzzing i jak wykorzystać narzędzie AFL do automatycznego wykrywania błędów i luk w oprogramowaniu, zwiększając bezpieczeństwo.
Spis treści
- Co to jest Fuzzing? Definicja i Zastosowanie w Testowaniu Oprogramowania
- Jak Działa Fuzzer AFL: Najważniejsze Funkcje i Zalety
- Praktyczne Kroki: Rozpoczęcie Fuzzowania z AFL
- Fuzzing w Kontekście Bezpieczeństwa i Ochrony Przed Zagrożeniami
- Najczęstsze Błędy Znajdowane przez Fuzzery
- Podsumowanie: Czy Fuzzing to Przyszłość Bezpieczeństwa Oprogramowania?
Co to jest Fuzzing? Definicja i Zastosowanie w Testowaniu Oprogramowania
Fuzzing, zwany również fuzz testowaniem, to zaawansowana metoda automatycznego testowania bezpieczeństwa i jakości oprogramowania, polegająca na generowaniu oraz wprowadzaniu do badanej aplikacji dużych ilości losowych, nieprzewidywalnych lub umyślnie zniekształconych danych wejściowych (tzw. fuzzów). Głównym celem tej techniki jest wyszukiwanie nieoczekiwanych zachowań programu takich jak awarie, wyjątki, przecieki pamięci, czy potencjalne luki bezpieczeństwa, które mogłyby zostać wykorzystane do ataku przez osoby nieuprawnione. Fuzzing jest niezwykle skuteczny, ponieważ symuluje ataki lub nietypowe sytuacje, które często bywają pomijane podczas tradycyjnych, ręcznych testów oprogramowania. Dzięki temu umożliwia wykrywanie błędów, których nie są w stanie ujawnić inne formy testowania, takie jak testy jednostkowe czy analiza statyczna kodu. Testowanie za pomocą fuzzingu można przeprowadzać zarówno na poziomie pojedynczych funkcji, jak i całych systemów, co czyni tę metodę uniwersalnym narzędziem przy ocenie odporności aplikacji na nietypowe dane.
W praktyce fuzzing znajduje zastosowanie w wielu dziedzinach rozwoju i utrzymania oprogramowania, zarówno komercyjnego, jak i open-source’owego. Szczególnie istotną rolę odgrywa w testowaniu aplikacji systemowych, przeglądarek internetowych, bibliotek sieciowych oraz rozwiązań stosowanych w branży embedded czy IoT, gdzie bezpieczeństwo i niezawodność mają krytyczne znaczenie. Proces fuzzowania polega najczęściej na uruchamianiu badanego programu z losowo generowanymi danymi wejściowymi i monitorowaniu jego działania – jeśli dojdzie do awarii, crasha lub błędu, tester otrzymuje informacje pozwalające na dalszą diagnozę i analizę przyczyny problemu. Narzędzia do fuzzingu, takie jak American Fuzzy Lop (AFL), automatyzują wszystkie etapy procesu, generując odpowiednie przypadki testowe, rejestrując wyniki i identyfikując newralgiczne miejsca w kodzie. Dzięki temu fuzz testing umożliwia szybką, obiektywną ocenę odporności programu na błędne lub złośliwie przygotowane dane, ułatwiając spełnienie wymagań bezpieczeństwa oraz wspierając proces doskonalenia jakości kodu. Fuzzing wykorzystywany jest także do testowania implementacji protokołów, parserów plików, interfejsów API, a nawet urządzeń sprzętowych, pomagając programistom i specjalistom ds. bezpieczeństwa w identyfikacji i eliminacji podatności, zanim zostaną one wykorzystane w warunkach produkcyjnych lub przez potencjalnych cyberprzestępców.
Jak Działa Fuzzer AFL: Najważniejsze Funkcje i Zalety
American Fuzzy Lop (AFL) to jeden z najbardziej popularnych i skutecznych fuzzerów open-source, który zrewolucjonizował podejście do automatycznego testowania bezpieczeństwa oprogramowania. Główną cechą wyróżniającą AFL jest jego zdolność do inteligentnego generowania i modyfikowania danych wejściowych na podstawie analizy pokrycia kodu (ang. code coverage). Fuzzer ten operuje w trybie „coverage-guided fuzzing”, co oznacza, że śledzi, które fragmenty kodu zostały już wykonane podczas testów i dynamicznie dostosowuje strategię mutacji wejść, aby odkrywać nowe, nieprzetestowane ścieżki wykonania. Dzięki temu AFL skutecznie zwiększa szanse wykrycia błędów, takich jak przepełnienia bufora, wycieki pamięci, nieoczekiwane wyjątki czy sytuacje wywołujące zawieszenie programu. Narzędzie to jest wyjątkowo łatwe w integracji – wystarczy przekompilować testowany program za pomocą kompilatora wspierającego AFL (np. clang lub gcc z odpowiednią łatką), dzięki czemu automatycznie wprowadzane są niezbędne punkty monitorowania w kodzie wykonywalnym. Po uruchomieniu fuzzera, proces testowania jest niemal całkowicie zautomatyzowany: użytkownik przekazuje minimalny zestaw początkowych danych wejściowych (tzw. seed corpus), które są następnie wielokrotnie mutowane i coraz skuteczniej wykorzystywane do odkrywania nowych dróg działania programu. Jedną z kluczowych zalet AFL jest efektywna obsługa równoległości – narzędzie pozwala uruchamiać wiele instancji jednocześnie, znacznie zwiększając liczbę testowanych przypadków i skracając czas potrzebny do znalezienia poważnych defektów. AFL automatycznie wykrywa błędy typu crash i samodzielnie tworzy szczegółowe logi, zawierające informacje przydatne w procesie debugowania, a także pozwala na szybkie odtworzenie warunków prowadzących do błędu. Narzędzie wspiera również tzw. persistent mode, umożliwiający testowanie aplikacji bez konieczności jej ciągłego restartowania, co dodatkowo podnosi wydajność pracy i minimalizuje koszty obliczeniowe. AFL doskonale sprawdza się zarówno przy testowaniu programów trybu tekstowego, jak i aplikacji obsługujących bardziej złożone formaty danych, np. pliki binarne czy komunikację protokołową.
Stosowanie fuzzera AFL niesie za sobą konkretne korzyści dla zespołów deweloperskich i specjalistów ds. bezpieczeństwa. Przede wszystkim pozwala na wczesne wykrywanie i eliminowanie podatności, zanim oprogramowanie trafi do produkcji, znacząco ograniczając koszty związane z późniejszym usuwaniem błędów czy reagowaniem na incydenty bezpieczeństwa. Automatyzacja i skalowalność AFL otwierają przed organizacjami możliwość testowania dużych projektów przy minimalnym nakładzie pracy manualnej, co jest szczególnie istotne w środowiskach DevSecOps czy ciągłej integracji. Innowacyjne algorytmy mutacji AFL – wykorzystujące takie techniki jak bitflipping, generowanie losowych wartości czy inteligentne przestawianie segmentów wejściowych – sprawiają, że narzędzie potrafi doskonale eksplorować potencjalnie niebezpieczne fragmenty kodu, które mogą być pomijane podczas klasycznych testów jednostkowych. AFL został także wyposażony w mechanizmy minimalizacji przypadków testowych, pozwalając szybko określić najmniejszy możliwy zestaw danych konieczny do odtworzenia błędu, co ułatwia analizę i przyspiesza naprawę. Jego uniwersalność przejawia się nie tylko w obsłudze wielu typów aplikacji, ale również w możliwości łatwego rozszerzania funkcjonalności za pośrednictwem licznych pluginów społeczności, integracji z narzędziami do analizy statycznej i dynamicznej oraz wsparcia dla systemów rozproszonych i chmurowych. Wszystkie te cechy sprawiają, że AFL uznawany jest za narzędzie nie tylko efektywne, lecz także wyjątkowo elastyczne, które może być używane zarówno do szybkich testów ad hoc, jak i długotrwałych, zaawansowanych kampanii fuzzujących.
Praktyczne Kroki: Rozpoczęcie Fuzzowania z AFL
Rozpoczęcie pracy z AFL wymaga przygotowania kilku kluczowych elementów i poznania podstawowych kroków, które pozwolą wykorzystać pełny potencjał tego narzędzia. Pierwszym krokiem jest pobranie oraz instalacja AFL – oficjalne repozytorium znajduje się na GitHubie, a proces instalacji jest dobrze udokumentowany i zazwyczaj ogranicza się do kilku poleceń make w systemach Linux. AFL działa najefektywniej z aplikacjami, które można skompilować samodzielnie, gdyż wymaga instrumentacji kodu na etapie kompilacji, co polega na użyciu specjalnych wersji kompilatorów: afl-gcc lub afl-clang. Dzięki temu fuzzer może analizować, które części programu są wykonywane podczas testowania rozmaitych wejść. Kolejnym nieodzownym elementem jest przygotowanie tzw. seed corpus, czyli początkowego zbioru plików lub danych wejściowych, które reprezentują przykładowe i poprawne wejścia do testowanego programu. Seed corpus powinno być zróżnicowane, aby zwiększyć efektywność fuzzowania – nawet kilka prostych plików tekstowych, BIN, JSON lub innych odpowiednich do formatu wejściowego aplikacji potrafi znacząco przyspieszyć eksplorację kodu przez AFL. Po przygotowaniu seed corpus oraz instrumentacji programu można uruchomić fuzzowanie za pomocą prostego polecenia w konsoli, zwykle w formacie: afl-fuzz -i [folder_z_inputami] -o [folder_z_wynikami] -- ./program_testowany [args]. Parametry te wskazują katalog wejściowy i wyjściowy oraz sam program, czasami z dodatkowymi argumentami, np. ścieżką do pliku wejściowego przekazywaną jako @@. Proces ten można łatwo skalować, uruchamiając kilka instancji AFL (tryb master/slave), co pozwala wykorzystać moc wielordzeniowych procesorów oraz przyspieszyć znajdowanie nowych ścieżek w kodzie.
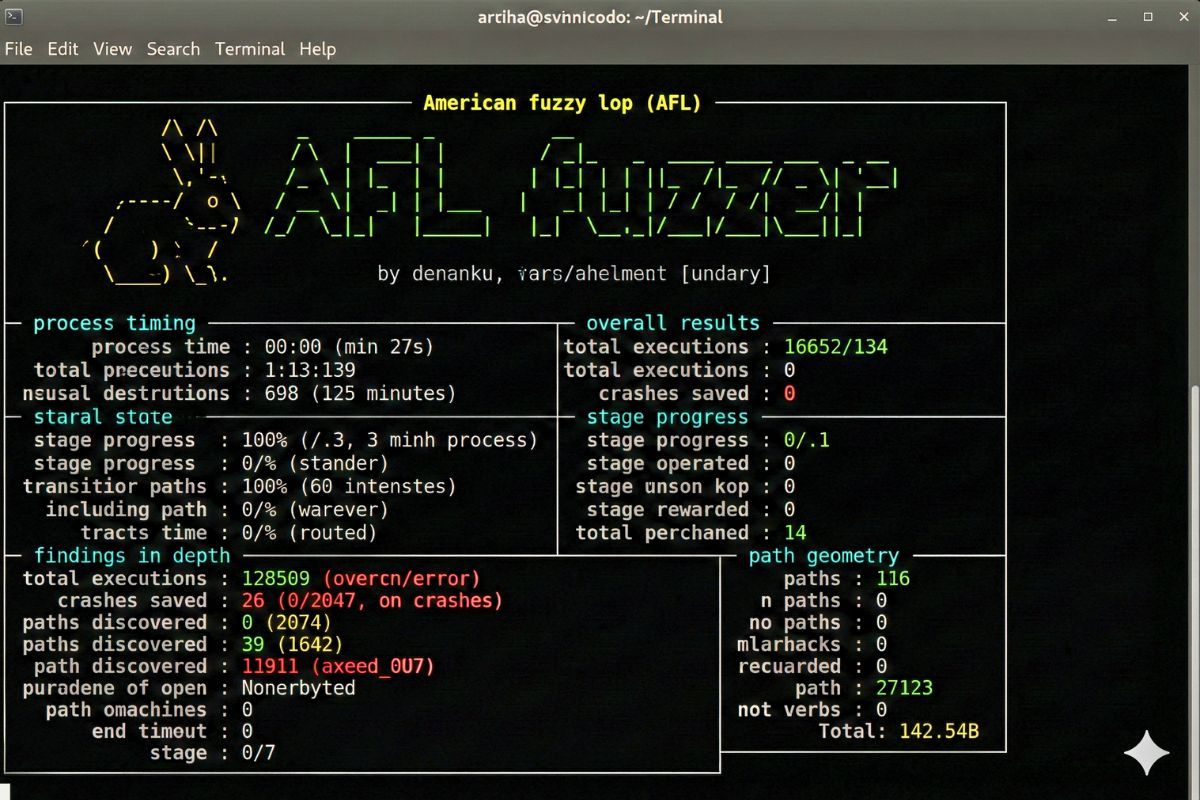
Ważną częścią pracy z fuzzingiem przy użyciu AFL jest również konfiguracja środowiska i monitorowanie postępów testów. Wyniki działania fuzzera rejestrowane są w katalogu wyjściowym (output), gdzie znajdują się logi, katalogi z różnymi przypadkami testowymi oraz podfoldery takie jak crashes i hangs, gromadzące wejścia powodujące awarie lub „zawieszki” programu. Regularna analiza tych plików pozwala na szybkie wychwycenie poważnych błędów, które mogą prowadzić do realnych exploitów. Optymalizując środowisko testowe, warto zadbać o ograniczenie wszelkich czynników mogących zakłócić niezależność i powtarzalność testów, w tym wyłączenie mechanizmów automatycznego restartowania procesu czy minimalizację wpływu kodów losowych w aplikacji. Dla zaawansowanych użytkowników dostępne są opcje takie jak persistent mode, który znacznie przyspiesza fuzzowanie aplikacji typu parser lub serwer, poprzez wielokrotne testowanie wejścia bez każdorazowego restartowania procesu. Można też ustawiać limity timeoutu na procesy oraz korzystać z funkcji minimalizacji przypadków testowych (afl-tmin), co pozwala uprościć analizę powstałych crashy. AFL oferuje również szeroki zakres integracji – wyniki mogą być weryfikowane innymi narzędziami (np. sanitizers), a sam proces automatycznego fuzzowania można zintegrować z CI/CD. Poprzez staranną konfigurację środowiska, dobór różnorodnego seed corpus i konsekwentną analizę wyników, nawet początkujący użytkownicy mogą efektywnie wykrywać błędy w oprogramowaniu, podnosząc bezpieczeństwo i jakość kodu.
Fuzzing w Kontekście Bezpieczeństwa i Ochrony Przed Zagrożeniami
Fuzzing, stanowiący fundament współczesnych strategii zapewniania bezpieczeństwa, odgrywa kluczową rolę w aktywnej ochronie przed zagrożeniami pojawiającymi się na każdym etapie cyklu życia oprogramowania. W kontekście bezpieczeństwa IT, jego przewaga nad tradycyjnymi metodami testowania wynika z automatyzacji i zdolności do wykrywania nieprawidłowości, które mogą prowadzić do podatności takich jak remote code execution, deserializacja niebezpiecznych danych, przepełnienia bufora, podatności typu use-after-free czy błędów logiki aplikacji. W odróżnieniu od audytów manualnych czy klasycznych testów jednostkowych, fuzzing umożliwia eksplorację tych obszarów kodu, które z pozoru wydają się bezpieczne bądź zostały zignorowane podczas standardowych przeglądów. Jego istotną zaletą jest „nieprzewidywalność” danych wejściowych oraz masowa skala testowania, która pozwala ujawniać rzadko spotykane, ale potencjalnie poważne luki i błędy. Dzięki temu programiści, inżynierowie bezpieczeństwa i zespoły DevOps mogą na bieżąco reagować na pojawiające się zagrożenia, minimalizując ryzyko późniejszych ataków wykorzystujących nieznane wcześniej podatności zeroday, które jeszcze nie trafiły do publicznych baz CVE i stanowią ogromne zagrożenie dla biznesu. W środowiskach o wysokich wymaganiach dotyczących ochrony (np. fintech, Przemysł 4.0, systemy IoT, sektor publiczny), fuzzing jest stosowany zarówno wewnętrznie, jak i zewnętrznie, pozwalając identyfikować luki nie tylko na poziomie kodu źródłowego, ale również w zależnościach, bibliotekach, parserach protokołów i innych komponentach narażonych na niekontrolowany input. Przeprowadzenie regularnego fuzzowania staje się nieodzownym elementem cyklicznych audytów bezpieczeństwa, testów zgodności z regulacjami branżowymi (np. RODO, PCI DSS) oraz wdrażania praktyk secure by design, gdzie bezpieczeństwo jest fundamentem architektury oprogramowania, a nie dodatkiem na późniejszych etapach rozwoju produktu.
Zastosowanie fuzzingu w kontekście odporności na zagrożenia cybernetyczne to również szeroko rozumiana profilaktyka, polegająca na neutralizowaniu zagrożeń zanim zostaną wykorzystane przez napastników. Fuzzery takie jak AFL potrafią automatycznie generować i poddawać analizie setki tysięcy, a nawet miliony zmutowanych przypadków testowych w krótkim czasie, co pozwala na skuteczne ujawnianie anomalii funkcjonowania oprogramowania i umożliwia szybkie reagowanie na wykryte błędy. Automatyczne logowanie i agregacja wyników ułatwiają analizę podatności, co wspiera zarządzanie podatnościami (Vulnerability Management) i szybką reakcję zespołów odpowiedzialnych za naprawę błędów (Incident Response). Szczególną wartość fuzzing wykazuje w testowaniu oprogramowania sieciowego, parserów formatów plikowych czy interfejsów API, które są narażone na nieautoryzowane ataki polegające na przesyłaniu nietypowych lub złośliwie przygotowanych danych – typowe wektory dla przeprowadzania exploitacji. Metodyka ta zyskuje również znaczenie w kontekście rozwoju oprogramowania typu open source, gdzie szybka identyfikacja i naprawa luk ma wpływ na tysiące, a nawet miliony końcowych użytkowników na całym świecie. W połączeniu z automatyzacją pipeline’ów CI/CD, fuzzing jest nieoceniony w tworzeniu procesów secure development lifecycle (SDL), gwarantując, że każda aktualizacja kodu przechodzi rygorystyczne testy narażeniowe. Warto podkreślić, że skuteczność fuzzingu jako narzędzia ochrony przed zagrożeniami zależy także od świadomości zespołów developerskich oraz ich zdolności szybkiego reagowania na zgłoszone błędy. Odpowiednie wdrożenie fuzzingu (w tym integracja z systemami ticketowania, automatyczną analizą crashów i retrospektywą przypadków testowych) sprawia, że organizacja nie tylko podnosi swój poziom bezpieczeństwa, ale zyskuje przewagę konkurencyjną poprzez proaktywne zarządzanie ryzykiem technologicznym – eliminując znacznie więcej problemów zanim zagrożą one ciągłości działania, reputacji czy poufności danych klientów.
Najczęstsze Błędy Znajdowane przez Fuzzery
Fuzzery, takie jak American Fuzzy Lop (AFL), są niezwykle skuteczne w wykrywaniu szerokiego spektrum podatności programistycznych, z których wiele pozostaje niedostrzeżonych podczas tradycyjnych testów jednostkowych lub manualnych przeglądów kodu. Najbardziej rozpoznawalnymi błędami wychwytywanymi przez fuzzery są przepełnienia bufora, w tym przepełnienia stosu (stack buffer overflow) oraz sterty (heap buffer overflow). Tego typu błędy pojawiają się, gdy program pozwala na zapisanie większej ilości danych niż zadeklarowano w buforze, prowadząc do nadpisania pamięci i często umożliwiając atakującym wykonanie nieautoryzowanego kodu lub spowodowanie awarii systemu. Innym bardzo powszechnym problemem detekowanym przez fuzzery są błędy związane z zarządzaniem pamięcią, takie jak use-after-free (dostęp do pamięci po jej zwolnieniu), double free (wielokrotne zwolnienie tego samego fragmentu pamięci) czy wycieki pamięci (memory leaks). Szczególnie groźne są przypadki use-after-free, które mogą prowadzić do niestabilności aplikacji, korupcji danych oraz potencjalnie otwierać drogę do eskalacji uprawnień przez atakujących. Fuzzery często wykrywają także błąd odczytu poza granicą bufora (out-of-bounds read), gdy aplikacja odczytuje dane spoza zadeklarowanego obszaru pamięci, co może prowadzić do ujawnienia wrażliwych informacji. Niezwykle wartościowym aspektem stosowania fuzzingu jest możliwość wykrycia całych klas błędów logicznych, jak nieprawidłowa obsługa wyjątków, niewłaściwa walidacja danych wejściowych czy niewłaściwe wywołania funkcji systemowych, które mogą skutkować zawieszeniem aplikacji, niespodziewanymi błędami lub narażeniem na ataki DoS (Denial of Service).
Kolejnymi typowymi błędami wykrywanymi przez fuzzery są różnego rodzaju „crashe” aplikacji wynikające z nieodpowiedniego przetwarzania danych wejściowych – zarówno tych całkowicie losowych, jak i celowo zniekształconych. Przykładem mogą być błędy parserów plików, zwłaszcza w aplikacjach przetwarzających pliki multimedialne, dokumenty tekstowe czy archiwa, gdzie nieprzewidziana kombinacja bajtów może prowadzić do zawieszenia lub awarii programu. Fuzzery wykrywają również niespójności w implementacji protokołów komunikacyjnych oraz naruszenia integralności operacji wejścia/wyjścia, takich jak nieobsłużone wyjątki, błędy konwersji typu czy niewłaściwe rozpoznawanie końcówki pliku (EOF). W zakresie bezpieczeństwa, do najczęstszych wykrywanych podatności należą format string bugs (błędy formatowania napisów), integer overflow/underflow (przepełnienia lub niedomagania liczb całkowitych), race conditions (wyścigi wątków) oraz nieautoryzowane operacje odczytu/zapisu. Fuzzery skutecznie identyfikują także błędy związane z niepoprawnym zarządzaniem stanem aplikacji, na przykład nieprzewidziane przejścia stanów w maszynach stanowych, które mogą prowadzić do ujawniania się luk logicznych lub naruszeń autoryzacji. Dodatkowym atutem narzędzi takich jak AFL jest ich zdolność do wykrywania t.zw. edge-case bugs – nietypowych zachowań aplikacji, które objawiają się tylko przy bardzo specyficznych, rzadko występujących wejściach, przez co są niemal niemożliwe do wychwycenia klasycznymi metodami testowania. Dzięki temu fuzzery stanowią nieocenione narzędzie zarówno w fazie audytu bezpieczeństwa, jak i regularnego utrzymania oraz rozwoju oprogramowania.
Podsumowanie: Czy Fuzzing to Przyszłość Bezpieczeństwa Oprogramowania?
W dobie rosnącej złożoności oprogramowania oraz coraz wyraźniejszych zagrożeń cybernetycznych, fuzzing – a zwłaszcza narzędzia takie jak American Fuzzy Lop – wyraźnie zyskuje na znaczeniu w kontekście zapewniania bezpieczeństwa systemów IT. Dynamika rozwoju technologii, przenikanie nowoczesnych rozwiązań software’owych do infrastruktury krytycznej oraz wykładniczy wzrost powierzchni ataku sprawiają, że klasyczne techniki testowania przestają być wystarczające. Fuzzing, bazujący na automatycznym generowaniu i mutowaniu danych wejściowych oraz monitorowaniu zachowania programu, dostarcza narzędzi dostosowanych do wyzwań współczesności. Dzięki podejściu coverage-guided oraz integracji z potężnymi kompilatorami i frameworkami, fuzzery umożliwiają szybkie lokalizowanie błędów, które przy tradycyjnym testowaniu mogłyby pozostać niewykryte przez długi czas – lub nawet nigdy nie zostać zidentyfikowane przed pojawieniem się realnego zagrożenia. W praktyce oznacza to wyraźną zmianę w filozofii testowania: przejście od ręcznie budowanych przypadków testowych ku pełnej automatyzacji oraz eksploracji nieprzewidywalnych scenariuszy, jakie mogą wystąpić w produkcyjnym środowisku.
Automatyczne testowanie z wykorzystaniem fuzzingu staje się filarem nowoczesnych praktyk DevSecOps oraz secure development lifecycle, przyczyniając się nie tylko do minimalizacji kosztów wykrywania i naprawy podatności, ale również do podniesienia ogólnego poziomu cyberbezpieczeństwa całych organizacji. Fuzzing idealnie wpisuje się w obecne trendy, takie jak automatyzacja CI/CD, szybkie iterowanie wersji oprogramowania oraz konieczność natychmiastowej eliminacji błędów wykorzystywanych przez cyberprzestępców. Deweloperzy, testerzy i specjaliści ds. bezpieczeństwa coraz częściej wykorzystują fuzzery nie jako narzędzie wsparcia, lecz jako integralny, obowiązkowy element procesu utrzymania jakości i odporności kodu. Dzięki synergii z narzędziami analitycznymi, integracji ze środowiskami wirtualnymi (np. Docker, chmura), zdalnemu raportowaniu oraz zdolności do obsługi szerokiego wachlarza języków programowania, fuzzing staje się uniwersalnym rozwiązaniem – od testowania bibliotek, przez analizy protokołów, aż po zaawansowane audyty aplikacji webowych, mobilnych i IoT. Patrząc w przyszłość, możemy przewidywać dalszą ewolucję tej technologii. Oczekuje się, że rozwój sztucznej inteligencji oraz metod uczenia maszynowego jeszcze bardziej udoskonali mechanizmy mutacji, selekcji przypadków testowych oraz znajdowania anomalii, co przełoży się na efektywność i zasięg fuzzowania. Fuzzing już teraz stanowi fundament skutecznej walki z lukami zero-day, a jego znaczenie będzie nadal rosło – zarówno w dużych korporacjach sektora finansowego, przemysłowego czy infrastruktury krytycznej, jak i w dynamicznie rozwijającym się ekosystemie start-upów oraz społeczności open source. W miarę jak regulatorzy, dostawcy rozwiązań IT i klienci coraz mocniej zwracają uwagę na tematy związane z bezpieczeństwem cyfrowym, rozumienie i świadome wdrażanie fuzzingu powinno stać się standardem branżowym, skutkującym zwiększoną odpornością całych ekosystemów cyfrowych.
Podsumowanie
Fuzzing z użyciem narzędzia AFL to skuteczna metoda automatycznego wyszukiwania błędów i luk zabezpieczeń w oprogramowaniu. Dzięki zrozumieniu procesu fuzzowania, praktycznym wskazówkom dotyczącym korzystania z AFL i wiedzy o rodzajach wykrywanych błędów, firmy i deweloperzy mogą znacząco podnieść poziom bezpieczeństwa swoich aplikacji. Nowoczesne rozwiązania typu fuzzer stanowią nie tylko przyszłość testowania oprogramowania, ale już dziś są kluczowym elementem w walce z cyberzagrożeniami. Warto je wprowadzić do procesów QA, aby budować bezpieczniejszy ekosystem IT.

{kind=link}